Práce s Firebase je super, obzvlášť na hobby projekty. Je potřeba minimální nastavování infrastruktury, všechno funguje téměř out-of-the-box, máte k dispozici lokální emulátor většiny1 komponent Firebase a k tomu obří komunitu na StackOverflow a Slacku. Co víc si přát?
Možná obecně "čas" na hobby projekty, ale to je mimo rozsah tohoto příspěvku...
Prototypování jde od ruky, na všechno jsou SDKčka a dá se celkem rychle dostat z 0 na 1. Teda na 0.999 (~ téměř 1, ale ne tak docela). Poslední krok je po sobě uklidit předtím, než vám "běžný franta uživatel" udělá v datech totální paseku svým chováním ve vaší aplikaci. Nebo nedejbože nějaký floutek pokusí různé techniky k přístupu cizích dat. Jelikož je Firebase serverless platforma, spoustu byznys logiky je třeba implementovat na klientech.
Například čtení uživatelského dokumentu z Firestore lze udělat takto:
db.collection("users")
.whereField("id", isEqualTo: userId)
.addSnapshotListener { (snapshot, _) in
// procesování dat
}Pro dostání se z bodu A do bodu B je to fantazie - nemusím na všechno psát API endpointy, aplikace si s tím poradí. Chyba lávky. Nejenom, že si tímhle přečtu svoje data z databáze, já si tím dokonce přečtu všechna data z databáze.
Firestore Rules vstoupily do místnosti.
❌ Zabezpečení kolekce uživatelů #1
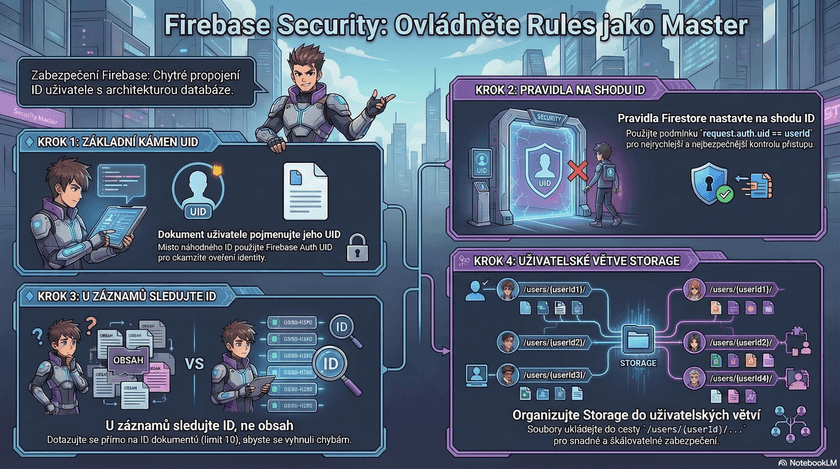
Naštěstí tedy existuje způsob, jak data zabezpečit tak, aby byly přístupné jen jejich majitelům. Po přečtení několika článků v rámci dokumentace jsem přistoupil k jednoduchému řešení:
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
match /users/{user} {
allow read: if isSignedIn()
&& request.auth.uid == resource.data.id;
}
}
function isSignedIn() {
return request.auth != null;
}
}Snažím se tu docílit toho, že když přistupuji k dokumentu v kolekci users, tak kontroluji, zda ID uživatele v tokenu odpovídá ID uloženému v dokumentu. Pro jednoduchost řekněme, že jeden dokument uživatele vypadá takto:
| Name | Value |
|---|---|
| id | string |
| string | |
| records | array |
Jednoduchá řešení jsou krásná v tom, že jsou jednoduchá. Nicméně jak bylo krásné, tak bylo k ničemu. Proč? Protože k přečtení dokumentu a porovnání IDček nemá uživatel dostatečná práva...
✅ Zabezpečení kolekce uživatelů #2
Zpátky na stromy! Tak co teď? Kde udělali soudruzi z NDR chybu? Ve struktuře dat! Problém je v tom, že ve skutečnosti je způsob, jak data (ne)číst a přitom zařídit správné nastavení ACL. Tak jak na to?
Vytvořit dokument v kolekci lze dvěma způsoby (příklad je z pohledu Node.js funkce):
firestore().collection("users").add(newUser)a nebo:
firestore().collection("users").doc(newUserId).set(newUser)První verze vytvoří dokument s automaticky vygenerovaném ID, druhý vytvoří dokument s daným ID. Druhý přístup má dva zásadní problémy:
- Pokud předem nezkontrolujete (ne)existenci klíče v kolekci, přepíšete cokoliv co tam předtím bylo.
- Vlastnoručně generovaná ID nemusí nutně mít lepší entropii (nebo kvalitu obecně) než automaticky generovaná.
První problém má jednoduché řešení (opět z pohledu Node.js funkce):
async userExists(id: string): Promise<boolean> {
const userDocument = await firestore().collection("users").doc(id).get();
return userDocument.exists;
}Druhý problém je vyřešen díky Firebase Auth - každý uživatel bude mít unikátní UID generováno na podobném principu jako ID pro dokumenty (win-win).
Dobře a co teď s tím? Vezměme si předchozí nástřel a upravme jej podle posledních změn ve struktuře dat:
match /users/{user} {
allow read: if isSignedIn() && request.auth.uid == user;
}A první boss je poražen! Dokonce už ani nemusíme dělat query .whereField("id", isEqualTo: userId) a přistupovat k dokumentu napřímo, jelikož uživatelovo ID je zároveň ID dokumentu. Fajn, tak co tam máme dál?
Zabezpečení kolekce přiřazených záznamů
Další krok je zabezpečení kolekce se záznamy, které jsou přiřazeny uživatelům (malý počet - např. se může jednat o seznam zařízení, kde je uživatel přihlášen). V tabulce uvedené výše se jedná o položku records - pole s IDčkama záznamů v jiné tabulce. Poučen z předchozích nezdarů jsem nejprve zmigroval pole z interních IDček na ID jednotlivých dokumentů v kolekci records.
⚠️ POZOR! Firestore nabízí jako jeden z typů pro hodnoty v dokumentu
Reference. Tento typ není pro naše účely vhodný, neboť se jedná o absolutní cestu k dokumentu. My potřebujeme pouze ID dokumentu.
Následně jsem přidal nové pravidlo:
match /records/{record} {
allow read: if isSignedIn()
&& resource.id in get(/databases/$(database)/documents/users/$(request.auth.uid)).data.records;
}Přichází ale komplikace - jak tato data číst na klientech? Doteď jsme je četli takto:
db.collection("records")
.whereField("id", in: recordIds)
.addSnapshotListener { (snapshot, _) in
// procesování dat
}Ale zase bychom se vraceli zpátky k tomu, že čteme OBSAH dokumentu. Pakliže se nachází v kolekci alespoň jeden dokument, ke kterému podle pravidel nemáme přístup, nemůžeme dělat query podle vnitřních hodnot.
"A teď jedna kontrolní soudruzi...jakpak se bude taková query chovat, když budeme porovnávat ID dokumentů, tedy nikoliv jejich obsah?"
Bingo.
db.collection("records")
.whereField(FieldPath.documentID(), in: recordIds)
.addSnapshotListener { (snapshot, _) in
// procesování dat
}Překvapivě tohle vůbec není zmíněno v dokumentaci - zakopnul jsem o to náhodou na StackOverflow. Co ale v dokumentaci je, je upozornění, že ve funkci whereField:in: je možno pouze vložit pole o maximální délce 10. To není moc a proto je třeba brát v potaz, zda není lepší pro větší počet přiřazených záznamů udělat subkolekci. V mém případě mi doména dovoluje použít pouze pole, neboť počet záznamů nepřekročí limit 10ti. Důležité ale teď je, že to jede a kolekce jsou zabezpečené. Druhý boss poražen. Čas na posledního.
Zabezpečení dat ve Storage
Posledním dílkem skládačky je Firebase Storage - bucket na jakákoliv data, v mém případě na profilové obrázky. Opět jsem hrál trochu ping-pong s rozdělením dat do podsložek, než jsem přišel na to, co bude pro mé účely fungovat nejlíp. Iterace byly následující:
/user_image/{id}/image.jpg/{id}/user_image/image.jpg/users/{id}/user_image/image.jpg
Iterace 1 nevyhovala protože pro každý další typ souboru patřící uživateli by muselo být další pravidlo. Iterace 2 nevyhovovala protože kořen bucketu by se s počtem uživatelů znepřehlednil pro cokoliv jiného než privátní uživatelská data. Iterace 3 řeší oba problémy dostatečně dobře.
rules_version = '2';
service firebase.storage {
match /b/{bucket}/o {
match /users/{user}/{filepath=**} {
allow read, write: if isSignedIn() && request.auth.uid == user;
}
}
function isSignedIn() {
return request.auth != null;
}
}Jediný problém je, že teď si může uživatel do své složky nahrát cokoliv. Ale to je možná na další příspěvek. Ať si tam nahrává třeba Inception v 4K. Hlavně, že to nemůže měnit ostatním uživatelům.
Závěrem bych chtěl jen zmínit, že oceňuji, že tým Firebase releasnul fajn video o zabezpečení Firebase dat. Týden potom, co jsem to rozluštil sám. Ale tak říká se, že "the path is the destination", že ano.
- Compound queries do Firestore vyžadující nastavení indexů na kolekci lokálně projdou ale v produkci spadnou.↩